Google'dan Çok Modlu Embedding
Google, metin, görsel, video, ses ve belgeleri tek bir vektör uzayında birleştiren ilk çok modlu embedding modeli Gemini Embedding 2'yi duyurdu. Model, Gemini API ve Vertex AI üzerinden herkese açık önizlemeye sunuldu.

Google, metin, görsel, video, ses ve belgeleri tek bir vektör uzayında birleştiren ilk çok modlu embedding modeli Gemini Embedding 2'yi duyurdu. Model, Gemini API ve Vertex AI üzerinden herkese açık önizlemeye sunuldu.
Google DeepMind, yapay zekâ araştırmacılarının ve geliştiricilerin uzun süredir beklediği bir yeniliği kullanıma açtı: Gemini Embedding 2. Bu model, metin, görsel, video, ses ve PDF belgelerini tek bir ortak vektör uzayında temsil edebilen ilk tam çok modlu embedding modeli olma özelliği taşıyor.
Modelin öne çıkan gücü, farklı veri türlerini ayrı ayrı işlemek zorunda kalmadan tek bir istek içinde birleştirebilmesi. Örneğin bir metin parçası ile bir görsel aynı anda modele gönderilebiliyor ve ikisi arasındaki anlamsal ilişki yakalanabiliyor. Metin tarafında 8192 token bağlam desteği sunan model; görsel için PNG ve JPEG formatlarında istek başına 6 görsele, video için 120 saniyeye kadar MP4 ve MOV dosyalarına, ses için ise transkripsiyon gerektirmeksizin doğrudan ses verisine destek veriyor. Bunlara ek olarak 6 sayfaya kadar PDF belgelerini de doğrudan işleyebiliyor. Model aynı zamanda 100'den fazla dili anlıyor ve önceki nesil embedding modellerine kıyasla metin, görsel ve video görevlerinde ölçülebilir bir performans artışı sunuyor.
Depolama ve maliyet dengesini yönetmek isteyenler için modele Matryoshka Representation Learning (MRL) tekniği uygulanmış. Bu yöntem, varsayılan 3072 boyuttan başlayarak vektör boyutunu esnek biçimde küçültmeye olanak tanıyor; 1536 ve 768 boyutlar da yüksek kaliteyi koruyarak kullanılabiliyor. Paramount Skydance'in erken erişim deneyimi, modelin pratikte ne kadar etkili olabileceğini somutlaştırıyor: Şirket, metin sorgusuyla transkripsiyonsuz video aramasında yüzde 85,3 Recall@1 oranına ulaştığını açıkladı. Gemini Embedding 2, şu an Gemini API ve Vertex AI üzerinden herkese açık önizleme kapsamında erişilebilir durumda.
Kaynak: Google

Steven Spielberg'in yeni bilim kurgu filmi Disclosure Day'in resmi fragmanı yayınlandı. Emily Blunt ve Josh O'Connor'lı yapım, hükümet sırlarını ve uzaylı varlığını konu alıyor.
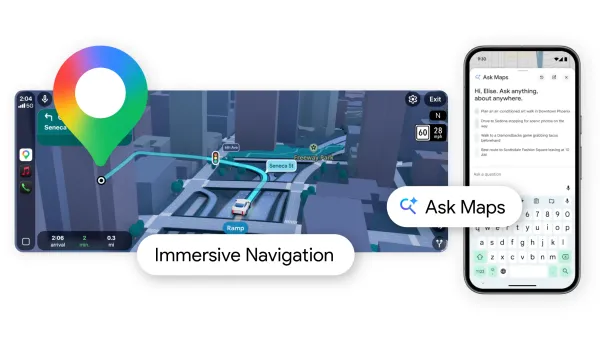
Google Maps, Gemini yapay zekasıyla iki büyük yenilik kazandı: Sohbet tabanlı yer keşfi sunan Ask Maps ve on yılın en kapsamlı navigasyon güncellemesi Immersive Navigation.

Disney+, mobil kullanıcılar için Verts adını verdiği dikey video keşif akışını ABD'de kullanıma sundu. Platform, bu özellikle izlenecek içerik bulma deneyimini baştan tasarlıyor.
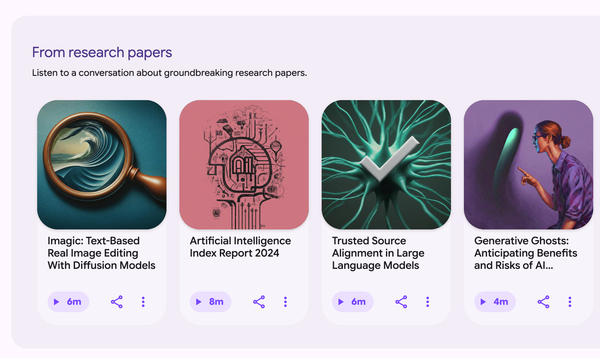
Google'ın deneysel yapay zekâ aracı Illuminate, akademik makaleleri dinlenebilir podcast formatına dönüştürüyor. Gemini destekli bu araç, karmaşık araştırmaları herkesin anlayabileceği sesli tartışmalara çeviriyor.
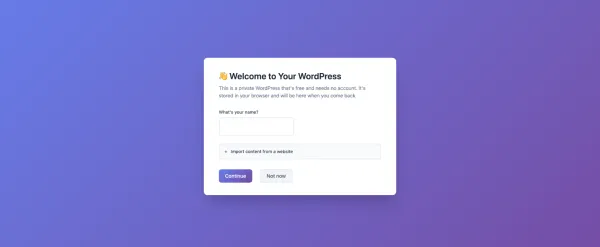
WordPress, tarayıcı tabanlı yeni platformu my.WordPress.net'i duyurdu. Kayıt olmadan, hosting seçmeden ve alan adı kararı vermeden doğrudan WordPress ortamına girilebiliyor.
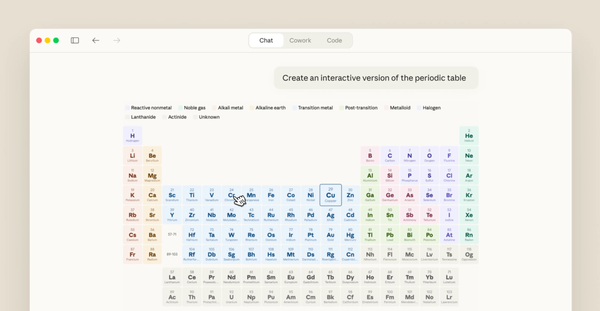
Anthropic, Claude'a sohbet içi interaktif grafik ve diyagram oluşturma özelliği ekledi. Yapay zekâ artık konuşmanın akışına göre anlık görseller üretiyor ve bunları kullanıcı isteğiyle güncelleyebiliyor.
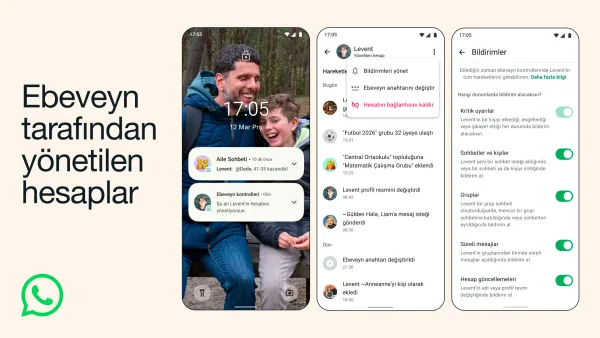
WhatsApp, çocuklar için ebeveyn tarafından yönetilen hesapları kullanıma sunuyor. Yeni özellik; kimin mesaj atabileceğinden grup üyeliklerine kadar pek çok ayarı ebeveynlerin kontrolüne bırakıyor.

Anthropic, güçlü yapay zekanın toplumlar üzerindeki etkilerini araştırmak için yeni bir kurum olan Anthropic Enstitüsü'nü hayata geçirdi.